
지난 9월 교내 데이터분석 학회에서 만난 3명의 학우들과 함께 빅콘테스트 데이터분석분야 퓨처스부문에 참가했다.
결론적으로 말하면 우리는 수상하지 못했다. 그럼에도 나는 빅콘을 위해 쏟아부었던 한두 달가량의 시간을 절대 후회하지 않는다.
내적으로든 외적으로는 정말 많은 것을 얻는 공모전이었기 때문이다. 사실 이 후기를 수상작들이 발표되고 난 후 우리의 탈락 원인을 분석하는 느낌으로 작성하려고 미뤄뒀었는데, 그러다 점점 까먹을 것 같아서 일단 작성한다.
추후에 수상작들이 공개되면 자세한 탈락원인 분석을 추가할 예정이다.
빅콘테스트는 국내 최대 규모의 데이터 분석 경연대회이다. 또한 굉장히 다양한 기업들이 참여하고 참가자들의 수준이나 데이터의 퀄리티 또한 높다. 그렇기에 머신러닝을 제대로 공부한 지도 얼마 안 되었고, 경험도 부족한 우리로써는 참가를 할지 말지 고민을 많이 했다.
참가만 해서 어영부영 하는 성격들이 아니기에 시작을 하면 어떻게 해서든 끝을 볼 걸 알았기 때문이다.
결국 우리가 내린 결정은 참가하자는 것이었다.
물론 최종목표가 조금 달랐다. 명시적으로는 당연히 수상이 목표였지만, 실질적으로는 경험을 쌓는 것이 목적이었다.
참가를 결정하게 된 원인 중 하나는 우리가 쉽게 접하지 못하는 실제 금융 앱 데이터를 다뤄볼 수 있다는 점이었다. 암호화를 거치고 약간의 정제를 거친 데이터이긴 했지만, 몇천만 개의 실제 금융 데이터는 흔치 않았기 때문이다.
또한 벽에 부딫혀보고 싶기도 했다. 지금까지 벽에 부딪히지 않았다는 게 아니다. 압도적인 데이터 앞에서 과연 내가 포기하지 않을 수 있는지를 시험해보고 싶었다. 이처럼 다양한 이유로 우리는 어쨌든 열심히 달려보자고 마음을 먹었다.
(이쁘게 노션 페이지도 만들었다)

사실 나의 블로그 특성상 깔끔한 정보전달이 목적이 아니라 일기형식으로 주저리주저리 쓰기 때문에 가독성이 좋지 않을 수 있다.
혹여나 빅콘테스트에 대한 정보를 얻고자 들어오신 분들이라면 대충 훑어보고 필요한 정보만 얻고 가시는 걸 권장한다..
https://www.bigcontest.or.kr/main.php
빅콘테스트
기업에서 실제 보유하고 있는 데이터를 자유롭게 활용하여 새로운 비즈니스 모델 및 참신한 아이디어를 제시하고, 빅데이터 인재발굴을 통한 청년 취업 기회를 제공
www.bigcontest.or.kr
* 대회 설명
1. 개요 : 앱 사용성 데이터를 통한 대출신청 예측분석
- 가명화된 데이터를 기반으로 고객의 대출상품 신청여부 예측
(2022년 3~5월 데이터제공 / 2022년 6월 예측) - 예측모델을 활용하여 탐색적 데이터 분석 수행
- 대출신청, 미신청 고객을 분류하여 고객의 특성 분석결과 도출
2. 평가 기준 : 1차 심사 - 고객 당 대출 신청 여부 예측, 데이터 수집, 전처리 과정, 예측 모델 해석(필수)
2차 심사 - 제출한 예측모델 및 분석방법에 대한 발표
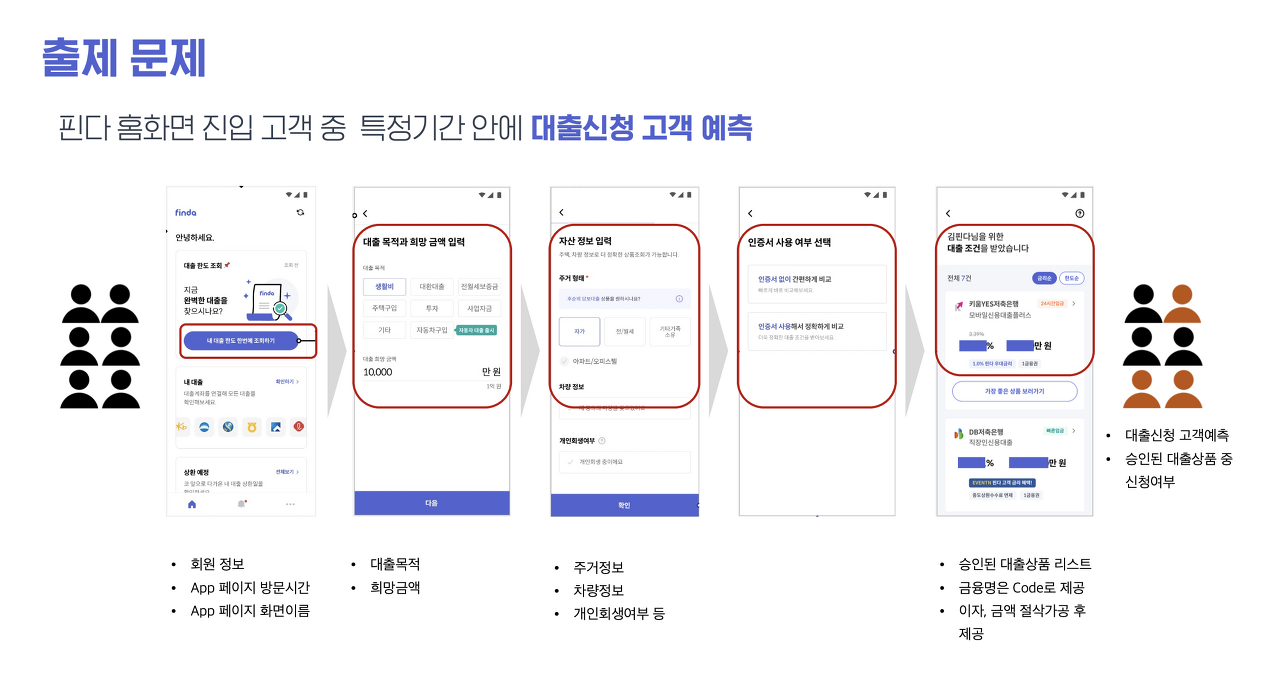
출제 문제는 다음과 같다.
1. 대출신청 고객을 예측하는 모델을 만들고
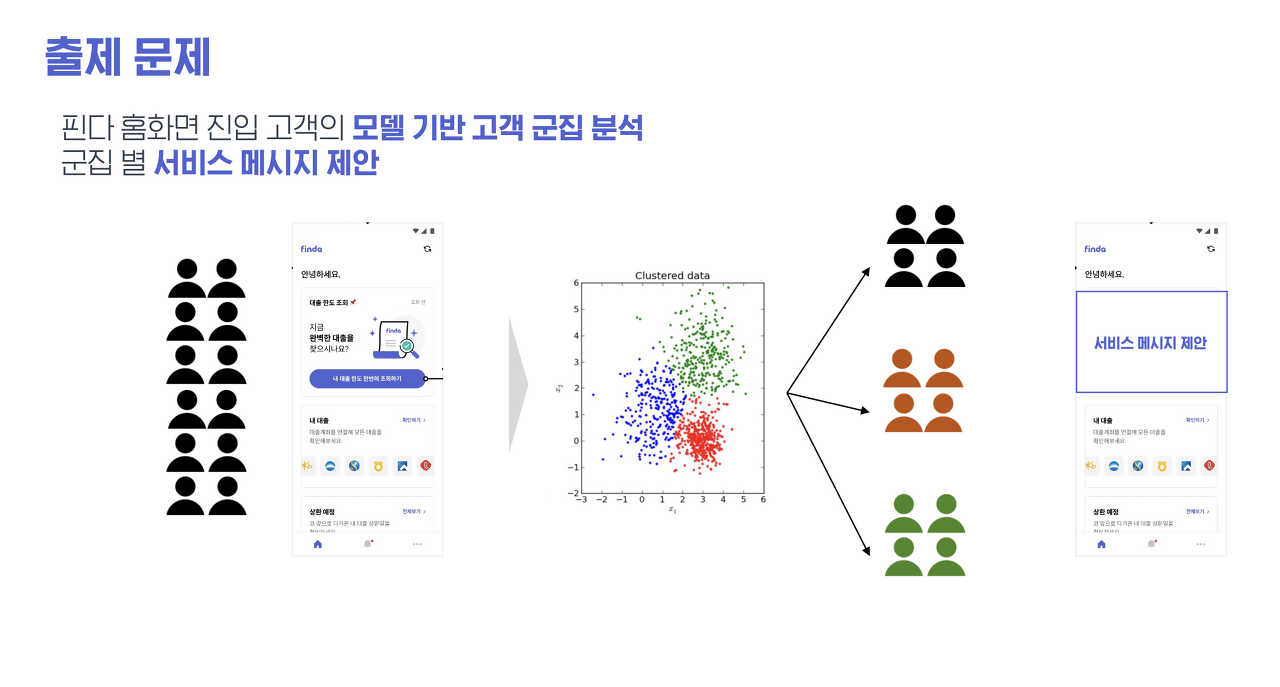
2. 고객 군집 분석 후 서비스 메시지 제안을 한다
총 2개의 문제를 풀어야 하는 셈인 것이었다.
* 데이터 설명
주어진 데이터는 간단하게 설명하자면 총 3개의 csv로 구성되어 있다.
유저의 신용정보, 사용자가 신청한 대출별 금융사별 승인결과, finda App 로그 정보
이렇게 말이다.
사실 데이터를 보고 며칠동안 헤맸다. 데이터 3개를 다 합쳐야 하나? 말아야 하나?
합쳐야 한다면 어떻게 합치지? 각각의 데이터 고객 수도 다르고, 신청서 번호도 다른데? 등등 궁금증이 쏟아져 나왔다.
결국 나름의 방법으로 해결했고 이후 잘 진행되었다. 물론 우리가 한 데이터 병합 방식이 최고의 방법이 아닐 수 있다.
하지만 우리의 생각으론 최선의 방법을 택했다..
* 코드 공유
자세한 분석 내용과 PPT 자료 등은 깃허브에 올려놓았다.
https://github.com/seopp/bigcontest
GitHub - seopp/bigcontest
Contribute to seopp/bigcontest development by creating an account on GitHub.
github.com
* 분석 전략
우리의 분석 목표는 다음과 같다
- 모델링을 통해 얻은 SHAP Value 해석을 통해 핀다의 프로모션 방향을 구체화
- 대출서비스를 이용한 고객과 이용하지 않은 고객으로 나누고, 군집화를 통해 군집을 나눈 후 각 군집 별 특성을 도출해내어 군집별 메시지를 제안
모델의 성능에 영향을 크게 미쳤던 주요 분석 전략으로는 다양한 파생변수 생성, 불균형 처리, 결측치 처리 방안 이었던 것 같다.
- 다양한 파생변수 생성
우리는 최대한 파생변수를 많이 생성하려고 노력했다. 모든 아이디어를 총동원해 파생변수를 생성하고 그중 성능 향상에 유의미한 변수들을 최종적으로 택했다. 사실 이 부분에서 시간을 많이 소요했던 것 같다. 하지만 성능을 크게 향상하는 파생변수를 생성해냈을 때는 정말 기뻤다. 사실 더 좋은 파생변수들을 생성해낼 수도 있었겠지만, 우리의 지식수준의 한계로 더 많이는 못 찾아낸 것 같다.
앞으로 데이터 분석 경연대회를 참가할 때도 가장 중요하게 봐야할 점이 파생변수인 것 같다. 모두가 같은 데이터로 성능을 이끌어낼 때는 독특한 파생변수로 차별점을 둘 수 있어야 하는 것 같다.
- 불균형 처리
주어진 데이터는 대출 신청 여부에 관한 데이터였기 때문에 심한 불균형 데이터였다. 아무래도 앱에 로그인해서 대출을 신청한 사람이 신청을 하지 않은 사람보다는 많이 적을 것이기 때문이다. 그렇기 때문에 이 불균형 데이터 처리 방안에 대해 굉장히 고민을 많이 했다.
여러 가지 Oversampling 기법들을 시도해보기도 하였고, Tree기반 모델들의 파라미터를 통해서도 불균형을 제어해 보았다.
워낙 데이터의 용량이 크다보니 Oversampling을 하면 Colab Pro의 24GB RAM으로도 감당하지 못할 만큼 램을 많이 잡아먹었다.
따라서 파라미터를 통해서 불균형 처리를 진행하였다.(아마 데이터의 용량을 줄이는 방법을 이때 알았다면 더 다양한 기법을 사용했을 수도)
불균형 데이터이기 때문에 또 하나의 추가적인 방법으로 threshold 변경을 통해 조금 더 보수적으로 대출 신청 여부를 판단했다.
대출을 신청하지 않는 사람들에 비해 대출을 신청하는 사람들의 비율은 소수이지만 비즈니스 관점에서는 신청하는 고객이 더 중요하다.
모델의 기본 threshold인 0.5는 불균형한 데이터에서 너무 많은 사람을 신청한다고 예측하기 때문에 손실이 많아질 수 있다.
따라서 threshold를 model metric을 기반으로 최적인 0.78로 설정함으로써 precision을 높이고 recall을 낮추었다. 이를 통해 f1-score 또한 향상할 수 있었다.
- 결측치 처리
실제 데이터인 만큼 결측치가 상당히 많았다. 또한 규칙성을 띄는 결측치 또한 매우 적어서 애를 먹었다.
이 과정에서는 결측치 처리 기법보다는 금융 지식을 쌓는 것에 노력했다. 일단 이 데이터의 특성을 꿰뚫고 있어야 결측치를 채우는 나름의 근거를 마련할 수 있다고 생각했기 때문이다. 이러한 과정을 통해 상당수의 결측치들을 도메인 지식을 활용해 채워 넣었고, 도저히 처리 방법이 마땅히 떠오르지 않는 데이터들은 knnimputer, iterativeimputer 등 을 활용해 채웠다.
* 마주쳤던 문제점
- 데이터 용량
총합 3천만개의 행으로 구성된 데이터는 분석을 함에 있어서 굉장한 걸림돌이었다.
하이퍼 파라미터를 튜닝함을 할 때에도, 전처리를 할 때에도, 모델을 돌릴 때에도 굉장히 많은 시간과 램을 잡아먹었다.
문제는 이 대회를 진행하면서 끝날 때까지 데이터 용량에 대한 처리를 하지 못하였었기 때문에
파일을 여러 개로 쪼개고 또 쪼개가며 최대한 램을 절약하고 시간을 절약하려 노력했다.
그럼에도 불구하고 자면서까지 모델을 돌려놓아야 했던 일이 기억난다.
이후 csv를 parquet형식으로 바꾸어 데이터를 다루는 방식을 알게 되었다.
이를 활용하면 데이터의 크기를 1/10로 줄일 수 있다는데,,
미리 찾아볼걸 후회했다. 하지만 이렇게 노가다했던 나의 경험은 끈기와 열정을 길러주는 데에 도움을 줬다고 생각하기로 했다^^..
- 시간 부족
빅콘테스트가 방학때부터 진행이 되었다면 참 좋았을 텐데, 작년과는 다르게 올해는 개강과 거의 동시에 대회가 시작했다.
기간도 한달 조금 넘는 시간이었기에 6전공과 또 다른 공모전을 병행해야 했던 나로서는 굉장히 힘든 시간이었다..
학과 공부를 거의 다 미뤄가며 공모전에만 몰두를 했음에도 불구하고 시험기간까지 공모전 마무리를 하느라 밤을 새웠다..
물론 결론적으로 보면 수상을 하지는 못하였기에 우리의 노력이 명시적인 성과로 드러나지 않았고, 나의 학점 또한 좋지 않았다.. ㅎㅎ
하지만 나는 후회하지 않는다!! 이번에 진행한 공모전들을 통해서 정말 울고 웃은 일들이 많았고 나 자신이 성장함을 느꼈기 때문이다.
다시 돌아간다면 난 같은 선택을 할 것 같다.
하지만 되도록 다음 빅콘테스트는 방학 때 시작했으면 참 좋을 것 같다..
* 우린 무엇을 위해 분석을 하고 있는가
분석을 진행하던 도중 문득 든 생각이다. 그래서 결국 이 분석을 해서 어디에 써먹을 수 있는 거지?
이러한 물음은 어떤 분석을 하던 가장 근본적이고 제일 먼저 고민해야 한다고 생각한다.
무작정 모델의 성능을 높이는 건 그리 중요하지 않을 수 있다.
결국 데이터 분석이라는 것은 어떤 거대한 프로젝트의 도구일 뿐이다.
분석하는 것 자체만으론 결론이 될 수 없다. 이 분석 결과를 가지고 무엇을 할 수 있는가, 회사 입장에서 이 분석을 통해 무엇을 향상시킬 수 있는가를 이끌어내야 한다.
그래서 앞으로 데이터 분석 경연대회를 진행할 때 꼭 명심해야 할 것들을 정리해 보았다.
- 명확한 주제 파악
- 주제를 명확히 파악해야 분석 방향 수립이 가능함
- 이 기업에서 왜 이 문제를 출제했을지, 이 문제를 통해 기업에서 가장 얻고자 하는 것이 무엇일지
- 주제와 기업의 니즈를 명확히 파악하여 어느 파트에 힘을 줄 것인지 등 분석 방향 수립하기
- 누구나 납득할 수 있는 스토리텔링
- 예측 성능이 1등이었던 적 x
- But, 탄탄한 스토리를 기반으로 정확한 메시지 전달
- PPT만 봐도 분석 주제, 사용한 데이터, 전처리, 모델링, 결과, 활용방안까지 이 팀이 어떻게 분석을 했는지 누구나 쉽게 이해할 수 있게끔 탄탄한 스토리를 구성하기
- 논리적이고 신선한 아이디어
- 같은 대회에 참가하는 모두가 같은 데이터로 같은 문제를 해결
- 남들과는 다른 차별성을 보여야 함
- 차별성은 데이터 분석 어느 단계에서도 보일 수 있음
- 데이터를 기반으로 도출한 논리적이고 신선한 아이디어를 적극 활용하여 성능을 끌어올리기
- 성능 vs 서비스
- 성능이 제일 중요한 task인지, 모델링을 통해 다른 가치를 창출하고자 하는지 파악 필요
- 분석이 얼마나 와닿을 수 있는지
- 평가지표/약간의 성능 향상에 너무 매몰되지 않는 게 필요
- 얼마나 좋은 모델인지는 성능보다는 모델링이 주는 가치에 기반
* 떨어진 원인 분석
- 추후 수상작이 올라오면 수정예정..
지난 9월 교내 데이터분석 학회에서 만난 3명의 학우들과 함께 빅콘테스트 데이터분석분야 퓨처스부문에 참가했다.
결론적으로 말하면 우리는 수상하지 못했다. 그럼에도 나는 빅콘을 위해 쏟아부었던 한두 달가량의 시간을 절대 후회하지 않는다.
내적으로든 외적으로는 정말 많은 것을 얻는 공모전이었기 때문이다. 사실 이 후기를 수상작들이 발표되고 난 후 우리의 탈락 원인을 분석하는 느낌으로 작성하려고 미뤄뒀었는데, 그러다 점점 까먹을 것 같아서 일단 작성한다.
추후에 수상작들이 공개되면 자세한 탈락원인 분석을 추가할 예정이다.
빅콘테스트는 국내 최대 규모의 데이터 분석 경연대회이다. 또한 굉장히 다양한 기업들이 참여하고 참가자들의 수준이나 데이터의 퀄리티 또한 높다. 그렇기에 머신러닝을 제대로 공부한 지도 얼마 안 되었고, 경험도 부족한 우리로써는 참가를 할지 말지 고민을 많이 했다.
참가만 해서 어영부영 하는 성격들이 아니기에 시작을 하면 어떻게 해서든 끝을 볼 걸 알았기 때문이다.
결국 우리가 내린 결정은 참가하자는 것이었다.
물론 최종목표가 조금 달랐다. 명시적으로는 당연히 수상이 목표였지만, 실질적으로는 경험을 쌓는 것이 목적이었다.
참가를 결정하게 된 원인 중 하나는 우리가 쉽게 접하지 못하는 실제 금융 앱 데이터를 다뤄볼 수 있다는 점이었다. 암호화를 거치고 약간의 정제를 거친 데이터이긴 했지만, 몇천만 개의 실제 금융 데이터는 흔치 않았기 때문이다.
또한 벽에 부딫혀보고 싶기도 했다. 지금까지 벽에 부딪히지 않았다는 게 아니다. 압도적인 데이터 앞에서 과연 내가 포기하지 않을 수 있는지를 시험해보고 싶었다. 이처럼 다양한 이유로 우리는 어쨌든 열심히 달려보자고 마음을 먹었다.
(이쁘게 노션 페이지도 만들었다)
사실 나의 블로그 특성상 깔끔한 정보전달이 목적이 아니라 일기형식으로 주저리주저리 쓰기 때문에 가독성이 좋지 않을 수 있다.
혹여나 빅콘테스트에 대한 정보를 얻고자 들어오신 분들이라면 대충 훑어보고 필요한 정보만 얻고 가시는 걸 권장한다..
https://www.bigcontest.or.kr/main.php
빅콘테스트
기업에서 실제 보유하고 있는 데이터를 자유롭게 활용하여 새로운 비즈니스 모델 및 참신한 아이디어를 제시하고, 빅데이터 인재발굴을 통한 청년 취업 기회를 제공
www.bigcontest.or.kr
* 대회 설명
1. 개요 : 앱 사용성 데이터를 통한 대출신청 예측분석
- 가명화된 데이터를 기반으로 고객의 대출상품 신청여부 예측
(2022년 3~5월 데이터제공 / 2022년 6월 예측) - 예측모델을 활용하여 탐색적 데이터 분석 수행
- 대출신청, 미신청 고객을 분류하여 고객의 특성 분석결과 도출
2. 평가 기준 : 1차 심사 - 고객 당 대출 신청 여부 예측, 데이터 수집, 전처리 과정, 예측 모델 해석(필수)
2차 심사 - 제출한 예측모델 및 분석방법에 대한 발표
출제 문제는 다음과 같다.
1. 대출신청 고객을 예측하는 모델을 만들고
2. 고객 군집 분석 후 서비스 메시지 제안을 한다
총 2개의 문제를 풀어야 하는 셈인 것이었다.
* 데이터 설명
주어진 데이터는 간단하게 설명하자면 총 3개의 csv로 구성되어 있다.
유저의 신용정보, 사용자가 신청한 대출별 금융사별 승인결과, finda App 로그 정보
이렇게 말이다.
사실 데이터를 보고 며칠동안 헤맸다. 데이터 3개를 다 합쳐야 하나? 말아야 하나?
합쳐야 한다면 어떻게 합치지? 각각의 데이터 고객 수도 다르고, 신청서 번호도 다른데? 등등 궁금증이 쏟아져 나왔다.
결국 나름의 방법으로 해결했고 이후 잘 진행되었다. 물론 우리가 한 데이터 병합 방식이 최고의 방법이 아닐 수 있다.
하지만 우리의 생각으론 최선의 방법을 택했다..
* 코드 공유
자세한 분석 내용과 PPT 자료 등은 깃허브에 올려놓았다.
https://github.com/seopp/bigcontest
GitHub - seopp/bigcontest
Contribute to seopp/bigcontest development by creating an account on GitHub.
github.com
* 분석 전략
우리의 분석 목표는 다음과 같다
- 모델링을 통해 얻은 SHAP Value 해석을 통해 핀다의 프로모션 방향을 구체화
- 대출서비스를 이용한 고객과 이용하지 않은 고객으로 나누고, 군집화를 통해 군집을 나눈 후 각 군집 별 특성을 도출해내어 군집별 메시지를 제안
모델의 성능에 영향을 크게 미쳤던 주요 분석 전략으로는 다양한 파생변수 생성, 불균형 처리, 결측치 처리 방안 이었던 것 같다.
- 다양한 파생변수 생성
우리는 최대한 파생변수를 많이 생성하려고 노력했다. 모든 아이디어를 총동원해 파생변수를 생성하고 그중 성능 향상에 유의미한 변수들을 최종적으로 택했다. 사실 이 부분에서 시간을 많이 소요했던 것 같다. 하지만 성능을 크게 향상하는 파생변수를 생성해냈을 때는 정말 기뻤다. 사실 더 좋은 파생변수들을 생성해낼 수도 있었겠지만, 우리의 지식수준의 한계로 더 많이는 못 찾아낸 것 같다.
앞으로 데이터 분석 경연대회를 참가할 때도 가장 중요하게 봐야할 점이 파생변수인 것 같다. 모두가 같은 데이터로 성능을 이끌어낼 때는 독특한 파생변수로 차별점을 둘 수 있어야 하는 것 같다.
- 불균형 처리
주어진 데이터는 대출 신청 여부에 관한 데이터였기 때문에 심한 불균형 데이터였다. 아무래도 앱에 로그인해서 대출을 신청한 사람이 신청을 하지 않은 사람보다는 많이 적을 것이기 때문이다. 그렇기 때문에 이 불균형 데이터 처리 방안에 대해 굉장히 고민을 많이 했다.
여러 가지 Oversampling 기법들을 시도해보기도 하였고, Tree기반 모델들의 파라미터를 통해서도 불균형을 제어해 보았다.
워낙 데이터의 용량이 크다보니 Oversampling을 하면 Colab Pro의 24GB RAM으로도 감당하지 못할 만큼 램을 많이 잡아먹었다.
따라서 파라미터를 통해서 불균형 처리를 진행하였다.(아마 데이터의 용량을 줄이는 방법을 이때 알았다면 더 다양한 기법을 사용했을 수도)
불균형 데이터이기 때문에 또 하나의 추가적인 방법으로 threshold 변경을 통해 조금 더 보수적으로 대출 신청 여부를 판단했다.
대출을 신청하지 않는 사람들에 비해 대출을 신청하는 사람들의 비율은 소수이지만 비즈니스 관점에서는 신청하는 고객이 더 중요하다.
모델의 기본 threshold인 0.5는 불균형한 데이터에서 너무 많은 사람을 신청한다고 예측하기 때문에 손실이 많아질 수 있다.
따라서 threshold를 model metric을 기반으로 최적인 0.78로 설정함으로써 precision을 높이고 recall을 낮추었다. 이를 통해 f1-score 또한 향상할 수 있었다.
- 결측치 처리
실제 데이터인 만큼 결측치가 상당히 많았다. 또한 규칙성을 띄는 결측치 또한 매우 적어서 애를 먹었다.
이 과정에서는 결측치 처리 기법보다는 금융 지식을 쌓는 것에 노력했다. 일단 이 데이터의 특성을 꿰뚫고 있어야 결측치를 채우는 나름의 근거를 마련할 수 있다고 생각했기 때문이다. 이러한 과정을 통해 상당수의 결측치들을 도메인 지식을 활용해 채워 넣었고, 도저히 처리 방법이 마땅히 떠오르지 않는 데이터들은 knnimputer, iterativeimputer 등 을 활용해 채웠다.
* 마주쳤던 문제점
- 데이터 용량
총합 3천만개의 행으로 구성된 데이터는 분석을 함에 있어서 굉장한 걸림돌이었다.
하이퍼 파라미터를 튜닝함을 할 때에도, 전처리를 할 때에도, 모델을 돌릴 때에도 굉장히 많은 시간과 램을 잡아먹었다.
문제는 이 대회를 진행하면서 끝날 때까지 데이터 용량에 대한 처리를 하지 못하였었기 때문에
파일을 여러 개로 쪼개고 또 쪼개가며 최대한 램을 절약하고 시간을 절약하려 노력했다.
그럼에도 불구하고 자면서까지 모델을 돌려놓아야 했던 일이 기억난다.
이후 csv를 parquet형식으로 바꾸어 데이터를 다루는 방식을 알게 되었다.
이를 활용하면 데이터의 크기를 1/10로 줄일 수 있다는데,,
미리 찾아볼걸 후회했다. 하지만 이렇게 노가다했던 나의 경험은 끈기와 열정을 길러주는 데에 도움을 줬다고 생각하기로 했다^^..
- 시간 부족
빅콘테스트가 방학때부터 진행이 되었다면 참 좋았을 텐데, 작년과는 다르게 올해는 개강과 거의 동시에 대회가 시작했다.
기간도 한달 조금 넘는 시간이었기에 6전공과 또 다른 공모전을 병행해야 했던 나로서는 굉장히 힘든 시간이었다..
학과 공부를 거의 다 미뤄가며 공모전에만 몰두를 했음에도 불구하고 시험기간까지 공모전 마무리를 하느라 밤을 새웠다..
물론 결론적으로 보면 수상을 하지는 못하였기에 우리의 노력이 명시적인 성과로 드러나지 않았고, 나의 학점 또한 좋지 않았다.. ㅎㅎ
하지만 나는 후회하지 않는다!! 이번에 진행한 공모전들을 통해서 정말 울고 웃은 일들이 많았고 나 자신이 성장함을 느꼈기 때문이다.
다시 돌아간다면 난 같은 선택을 할 것 같다.
하지만 되도록 다음 빅콘테스트는 방학 때 시작했으면 참 좋을 것 같다..
* 우린 무엇을 위해 분석을 하고 있는가
분석을 진행하던 도중 문득 든 생각이다. 그래서 결국 이 분석을 해서 어디에 써먹을 수 있는 거지?
이러한 물음은 어떤 분석을 하던 가장 근본적이고 제일 먼저 고민해야 한다고 생각한다.
무작정 모델의 성능을 높이는 건 그리 중요하지 않을 수 있다.
결국 데이터 분석이라는 것은 어떤 거대한 프로젝트의 도구일 뿐이다.
분석하는 것 자체만으론 결론이 될 수 없다. 이 분석 결과를 가지고 무엇을 할 수 있는가, 회사 입장에서 이 분석을 통해 무엇을 향상시킬 수 있는가를 이끌어내야 한다.
그래서 앞으로 데이터 분석 경연대회를 진행할 때 꼭 명심해야 할 것들을 정리해 보았다.
- 명확한 주제 파악
- 주제를 명확히 파악해야 분석 방향 수립이 가능함
- 이 기업에서 왜 이 문제를 출제했을지, 이 문제를 통해 기업에서 가장 얻고자 하는 것이 무엇일지
- 주제와 기업의 니즈를 명확히 파악하여 어느 파트에 힘을 줄 것인지 등 분석 방향 수립하기
- 누구나 납득할 수 있는 스토리텔링
- 예측 성능이 1등이었던 적 x
- But, 탄탄한 스토리를 기반으로 정확한 메시지 전달
- PPT만 봐도 분석 주제, 사용한 데이터, 전처리, 모델링, 결과, 활용방안까지 이 팀이 어떻게 분석을 했는지 누구나 쉽게 이해할 수 있게끔 탄탄한 스토리를 구성하기
- 논리적이고 신선한 아이디어
- 같은 대회에 참가하는 모두가 같은 데이터로 같은 문제를 해결
- 남들과는 다른 차별성을 보여야 함
- 차별성은 데이터 분석 어느 단계에서도 보일 수 있음
- 데이터를 기반으로 도출한 논리적이고 신선한 아이디어를 적극 활용하여 성능을 끌어올리기
- 성능 vs 서비스
- 성능이 제일 중요한 task인지, 모델링을 통해 다른 가치를 창출하고자 하는지 파악 필요
- 분석이 얼마나 와닿을 수 있는지
- 평가지표/약간의 성능 향상에 너무 매몰되지 않는 게 필요
- 얼마나 좋은 모델인지는 성능보다는 모델링이 주는 가치에 기반
* 떨어진 원인 분석
- 추후 수상작이 올라오면 수정예정..