
손실 함수(loss function)는 데이터를 토대로 산출한 모델의 예측 값과 실제 값의 차이를 표현하는 지표이다.
다시 말하면, 손실 함수는 모델 성능의 '나쁨'을 나타내는 지표인 것이다. (하지만, loss가 낮다고 해서 무조건적으로 더 '좋은' 모델인 것은 아니다.)
머신러닝 모델은 일반적으로 크게 회귀(regression)와 분류(classification)로 나누어볼 수 있다.
손실 함수도 이에 따라 두 가지로 나뉜다.
회귀에서 사용하는 대표적인 loss function은 MAE, MSE, RMSE 가 있다.
분류에서 사용하는 대표적인 loss function은 BCE(Binary Cross-Entropy), CE(Cross-Entropy)가 있다.
본 포스팅에서는 분류에서 사용하는 대표적인 loss function에 대해서 살펴보도록 한다.
먼저 Cross-Entropy Loss의 정의는 다음과 같다.

Binary Cross-Entropy Loss의 정의는 다음과 같다.
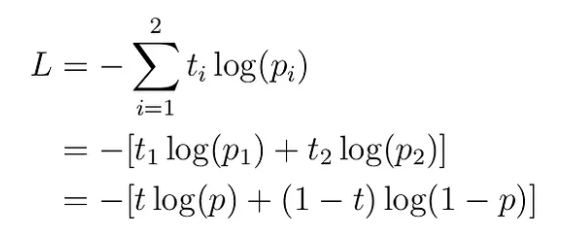
즉, BCE는 CE에서 n=2인 경우이다.
우리는 흔히 이진 분류 문제를 풀 때는 BCE를 사용하고 다중 분류 문제를 풀 때는 CE를 사용한다고 알고 있다.
하지만 이진 분류 문제를 풀 때에도 CE를 사용하는 경우를 많이 볼 수 있다. 왜 굳이 BCE를 놔두고 CE를 사용하는 것일까?
결론부터 말하자면 상관없다.
하지만 주의해야할 점이 있다.
우리가 흔히 Pytorch를 사용할 때, nn.CrossEntropyLoss()와 nn.BCELoss()를 사용하는데 이 두 함수에는 차이점이 있다.
nn.CrossEntropyLoss()는 내부적으로 Softmax() 함수가 포함되어 있는 반면, nn.BCELoss()는 그렇지 않다.
다시 말해, 이진 분류 문제에서 CE를 사용하든 BCE를 사용하든 차이가 없지만 Loss의 input으로 넣어주는 값으로 BCE는 Softmax를 취한 후에 넘겨줘야 한다는 것이다.
그렇다면 여기서 궁금증이 하나 더 생길 수 있다.
nn.CrossEntropyLoss()에서 Softmax()가 진행이 되는 거면 loss의 input으로는 꼭 logit값만 넣어줘야 하는 걸까?
- 정답은 없다. 하지만 loss가 갱신되는 정도의 차이는 있을 것이다. Softmax를 취한 후에 input으로 넘겨주면 차이가 작아지므로 loss의 업데이트 정도 또한 작아질 것이고, logit 값으로 넘겨주면 비교적 차이가 커지므로 loss의 업데이트 정도 또한 커질 것이다.