
Deep learning model inference time을 정확히 측정하는 법
- 요즘 ChatGPT, DALL-E 등 딥러닝 모델들이 많은 주목을 받고, 이에 따라 사용량 또한 급증하면서 모델을 사용할 때의 적은 inference time이 더욱 중요해지고 있다.
- 사용자 경험을 조금이라도 향상시키기 위해서는 밀리초 단위를 줄이는 것도 매우 중요할 것이다.
- 그렇기 때문에 model의 inference time을 잘 측정해야 하는데, 이를 측정하기 위해서는 비동기 처리에 대한 이해가 필요하다.
동기 처리(Synchronous execution) vs 비동기 처리(Asynchronous execution)
- 동기와 비동기의 차이점을 간단히 설명하면 동기는 직렬적으로 작동하는 방식이고, 비동기는 병렬적으로 작동하는 방식이다.
- 즉, 동기는 하나의 태스크가 끝날 때까지 기다렸다가 다음 태스크가 실행되고, 비동기는 한 번에 여러 태스크가 동시에 실행된다.
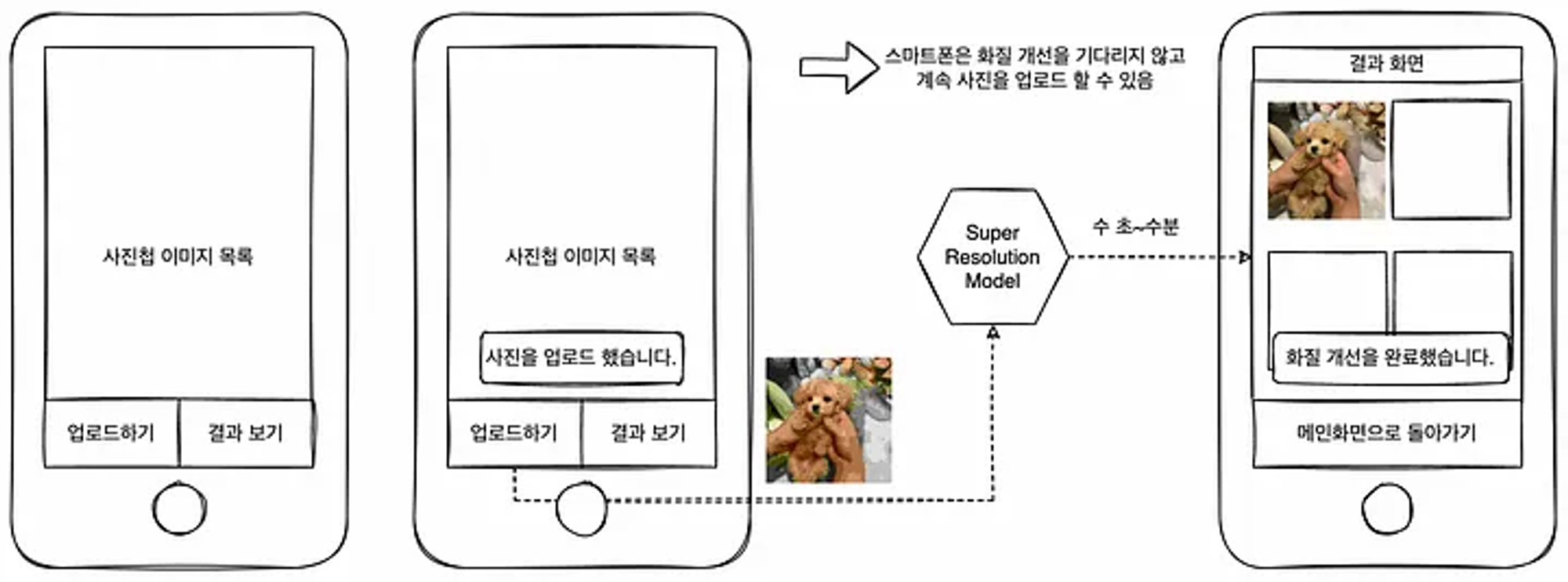
- 아래 그림을 보면 이해가 더 쉽다.

딥러닝 모델은 GPU를 사용하여 병렬적으로 처리해야 하기 때문에 비동기 처리가 거의 필수적이다.
비동기 처리가 필요한 이유는 크게 두 가지 관점에서 바라볼 수 있다.
Model inference time measure
model을 inference 할 때, 보통 batch 단위 처리를 사용하며, CPU에서 실행되는 작업과 GPU에서 실행되는 작업들이 존재한다. 만약 첫번째 batch가 GPU에서 forwarding 되고 있을 때, 이 작업이 다 끝날 때까지 CPU에서 아무것도 하지 않고 모든 과정을 기다리게 되면 매우 비효율적일 것이다. 그렇기 때문에 GPU에서 작업이 실행 중이더라도 CPU에서는 다음 batch를 처리할 수 있도록 해야 한다.
Model serving
딥러닝 모델을 구축해서 serving 하는 상황을 생각해 보자.
만약 동기 처리를 사용한다면, 사용자가 화면에서 서버로 데이터를 요청했을 때, 서버가 요청에 대한 응답을 줄 때까지 (모델이 inference를 마칠 때까지) 마냥 기다려야 한다. 하지만 비동기 처리를 사용한다면 사용자는 기다리지 않고도 다음 작업을 바로 수행할 수 있다.
예를 들어, 사진을 클라우드에 올리고 SR(Super Resolution)을 통해 화질을 개선해서 사용자에게 제공하는 어플이 있다고 가정해 보자.
이러한 앱에서는 파일 업로드하기 버튼을 누르고 난 다음의 처리를 비동기적으로 실시한다.
스마트폰 화면에 “사진을 업로드했습니다.”라는 푸시 메시지를 송신하고 화면은 사진첩을 유지한 채로 계속해서 업로드 작업을 할 수 있도록 처리하면 클라이언트의 조작을 멈추지 않고 SR 모델이 추론할 수 있는 시간을 확보할 수 있다. 추론이 완료된 이미지는 결과 보기 화면에 자동으로 추가되도록 한다면 사용자 경험은 좋을 것이다.
따라서 대부분의 딥러닝 모델을 서빙하는 상황에서는 클라이언트의 요청과 추론의 workflow을 비동기적으로 분리하고 있다.
Inference가 오래 걸리는 model을 serving 할수록 비동기 처리를 활용해서 사용자 경험을 향상시켜야 한다.
이처럼 비동기 처리는 매우 중요한 기능임에도 불구하고 딥러닝 모델의 inference time을 측정할 때는 문제가 생길 수 있다.
모델의 inference time을 측정할 때, 대부분의 사람들은 실제 경과 시간을 측정하는 것을 원할 것이다. 실제 환경에서 모델을 배포할 때 사용자가 경험할 latency를 파악해야 하기 때문이다.
모델의 inference time을 측정하는 방법 중 python의 time 라이브러리를 사용해 측정하는 방법이 있는데, time 라이브러리는 CPU에서 측정된다. 만약 모델이 CPU에서 동작한다면, 아래와 같이 time.perf_counter()를 사용하여 실제 경과 시간을 측정할 수 있다.
import time
model.eval() # 모델을 evaluation 모드로 설정
with torch.no_grad(): # Gradient 계산 비활성화
start = time.perf_counter()
output = model(input_tensor)
end = time.perf_counter()
print(f"Elapsed time on CPU: {end - start} seconds")
하지만 대부분의 딥러닝 모델은 GPU에서 동작한다. (모든 과정을 CPU에서 진행하는 경우는 거의 없을 것이다.)
만약 GPU에서 동작하는 모델을 time 라이브러리를 활용해서 측정한다면, GPU의 작업이 완료되지 않았는데도 불구하고 시간이 측정될 수 있다. 따라서 모델이 CUDA를 지원하는 GPU에서 동작한다면, 아래와 같이 torch.cuda.Event()를 사용하여 시간을 측정하는 것이 좋다. GPU 연산이 비동기적으로 수행되기 때문에 정확한 시간 측정을 위해서는 CUDA 이벤트와 동기화가 필요하기 때문이다.
import torch
model.eval() # 모델을 evaluation 모드로 설정
model = model.cuda() # 모델을 GPU로 이동
start_event = torch.cuda.Event(enable_timing=True)
end_event = torch.cuda.Event(enable_timing=True)
with torch.no_grad(): # Gradient 계산 비활성화
start_event.record()
output = model(input_tensor.cuda()) # 입력 데이터도 GPU로 이동
end_event.record()
torch.cuda.synchronize() # GPU 연산이 완료될 때까지 대기
time_taken = start_event.elapsed_time(end_event)
print(f"Elapsed time on GPU: {time_taken * 1e-3} seconds") # milliseconds to seconds
위의 방법을 사용하면 모델의 forward pass 동안의 실제 경과 시간을 정확하게 측정할 수 있다.
Deep learning model inference time을 정확히 측정하는 법
- 요즘 ChatGPT, DALL-E 등 딥러닝 모델들이 많은 주목을 받고, 이에 따라 사용량 또한 급증하면서 모델을 사용할 때의 적은 inference time이 더욱 중요해지고 있다.
- 사용자 경험을 조금이라도 향상시키기 위해서는 밀리초 단위를 줄이는 것도 매우 중요할 것이다.
- 그렇기 때문에 model의 inference time을 잘 측정해야 하는데, 이를 측정하기 위해서는 비동기 처리에 대한 이해가 필요하다.
동기 처리(Synchronous execution) vs 비동기 처리(Asynchronous execution)
- 동기와 비동기의 차이점을 간단히 설명하면 동기는 직렬적으로 작동하는 방식이고, 비동기는 병렬적으로 작동하는 방식이다.
- 즉, 동기는 하나의 태스크가 끝날 때까지 기다렸다가 다음 태스크가 실행되고, 비동기는 한 번에 여러 태스크가 동시에 실행된다.
- 아래 그림을 보면 이해가 더 쉽다.
딥러닝 모델은 GPU를 사용하여 병렬적으로 처리해야 하기 때문에 비동기 처리가 거의 필수적이다.
비동기 처리가 필요한 이유는 크게 두 가지 관점에서 바라볼 수 있다.
Model inference time measure
model을 inference 할 때, 보통 batch 단위 처리를 사용하며, CPU에서 실행되는 작업과 GPU에서 실행되는 작업들이 존재한다. 만약 첫번째 batch가 GPU에서 forwarding 되고 있을 때, 이 작업이 다 끝날 때까지 CPU에서 아무것도 하지 않고 모든 과정을 기다리게 되면 매우 비효율적일 것이다. 그렇기 때문에 GPU에서 작업이 실행 중이더라도 CPU에서는 다음 batch를 처리할 수 있도록 해야 한다.
Model serving
딥러닝 모델을 구축해서 serving 하는 상황을 생각해 보자.
만약 동기 처리를 사용한다면, 사용자가 화면에서 서버로 데이터를 요청했을 때, 서버가 요청에 대한 응답을 줄 때까지 (모델이 inference를 마칠 때까지) 마냥 기다려야 한다. 하지만 비동기 처리를 사용한다면 사용자는 기다리지 않고도 다음 작업을 바로 수행할 수 있다.
예를 들어, 사진을 클라우드에 올리고 SR(Super Resolution)을 통해 화질을 개선해서 사용자에게 제공하는 어플이 있다고 가정해 보자.
이러한 앱에서는 파일 업로드하기 버튼을 누르고 난 다음의 처리를 비동기적으로 실시한다.
스마트폰 화면에 “사진을 업로드했습니다.”라는 푸시 메시지를 송신하고 화면은 사진첩을 유지한 채로 계속해서 업로드 작업을 할 수 있도록 처리하면 클라이언트의 조작을 멈추지 않고 SR 모델이 추론할 수 있는 시간을 확보할 수 있다. 추론이 완료된 이미지는 결과 보기 화면에 자동으로 추가되도록 한다면 사용자 경험은 좋을 것이다.
따라서 대부분의 딥러닝 모델을 서빙하는 상황에서는 클라이언트의 요청과 추론의 workflow을 비동기적으로 분리하고 있다.
Inference가 오래 걸리는 model을 serving 할수록 비동기 처리를 활용해서 사용자 경험을 향상시켜야 한다.
이처럼 비동기 처리는 매우 중요한 기능임에도 불구하고 딥러닝 모델의 inference time을 측정할 때는 문제가 생길 수 있다.
모델의 inference time을 측정할 때, 대부분의 사람들은 실제 경과 시간을 측정하는 것을 원할 것이다. 실제 환경에서 모델을 배포할 때 사용자가 경험할 latency를 파악해야 하기 때문이다.
모델의 inference time을 측정하는 방법 중 python의 time 라이브러리를 사용해 측정하는 방법이 있는데, time 라이브러리는 CPU에서 측정된다. 만약 모델이 CPU에서 동작한다면, 아래와 같이 time.perf_counter()를 사용하여 실제 경과 시간을 측정할 수 있다.
import time
model.eval() # 모델을 evaluation 모드로 설정
with torch.no_grad(): # Gradient 계산 비활성화
start = time.perf_counter()
output = model(input_tensor)
end = time.perf_counter()
print(f"Elapsed time on CPU: {end - start} seconds")
하지만 대부분의 딥러닝 모델은 GPU에서 동작한다. (모든 과정을 CPU에서 진행하는 경우는 거의 없을 것이다.)
만약 GPU에서 동작하는 모델을 time 라이브러리를 활용해서 측정한다면, GPU의 작업이 완료되지 않았는데도 불구하고 시간이 측정될 수 있다. 따라서 모델이 CUDA를 지원하는 GPU에서 동작한다면, 아래와 같이 torch.cuda.Event()를 사용하여 시간을 측정하는 것이 좋다. GPU 연산이 비동기적으로 수행되기 때문에 정확한 시간 측정을 위해서는 CUDA 이벤트와 동기화가 필요하기 때문이다.
import torch
model.eval() # 모델을 evaluation 모드로 설정
model = model.cuda() # 모델을 GPU로 이동
start_event = torch.cuda.Event(enable_timing=True)
end_event = torch.cuda.Event(enable_timing=True)
with torch.no_grad(): # Gradient 계산 비활성화
start_event.record()
output = model(input_tensor.cuda()) # 입력 데이터도 GPU로 이동
end_event.record()
torch.cuda.synchronize() # GPU 연산이 완료될 때까지 대기
time_taken = start_event.elapsed_time(end_event)
print(f"Elapsed time on GPU: {time_taken * 1e-3} seconds") # milliseconds to seconds
위의 방법을 사용하면 모델의 forward pass 동안의 실제 경과 시간을 정확하게 측정할 수 있다.