BERT 개념 쉽게 이해하기
BERT는 Bidirectional Encoder Representations from Transformers
즉, Transformer의 Encoder 구조를 이용하여 문맥을 양방향으로 이해하는 모델이다.
BERT가 나오게 된 배경은 2018년 OpenAI에서 Transformer의 Decoder 구조를 사용하여 GPT-1을 출시했는데, 얼마 지나지 않아 구글에서 “GPT-1은 문맥이 중요한 Task인 QA나 LNI 등에서 좋지 않아 !!”라면서 BERT를 출시했다.
최근 OpenAI의 ChatGPT가 큰 화제를 얻자 이에 맞서 구글에서 Bard를 출시하는 것처럼
두 기업은 뭔가 경쟁 관계를 이어나가고 있는 것 같다. (그래서 NLP가 빠르게 발전할 수 있지 않을까?)
다시 본론으로 돌아와서 BERT는 MLM과 NSP 두 가지의 Task를 동시에 진행하는 모델이다.
여기서 MLM은 Masked language model 로써 양방향으로 마스킹된 토큰을 예측하는 방식이고
NSP는 Next sentence prediction 으로 [CLS] 토큰을 통해 두 개의 sentence가 실제로 corpus에서 바로 다음 sentence인지 아닌지를 판별하는 binary classification 방식이다.
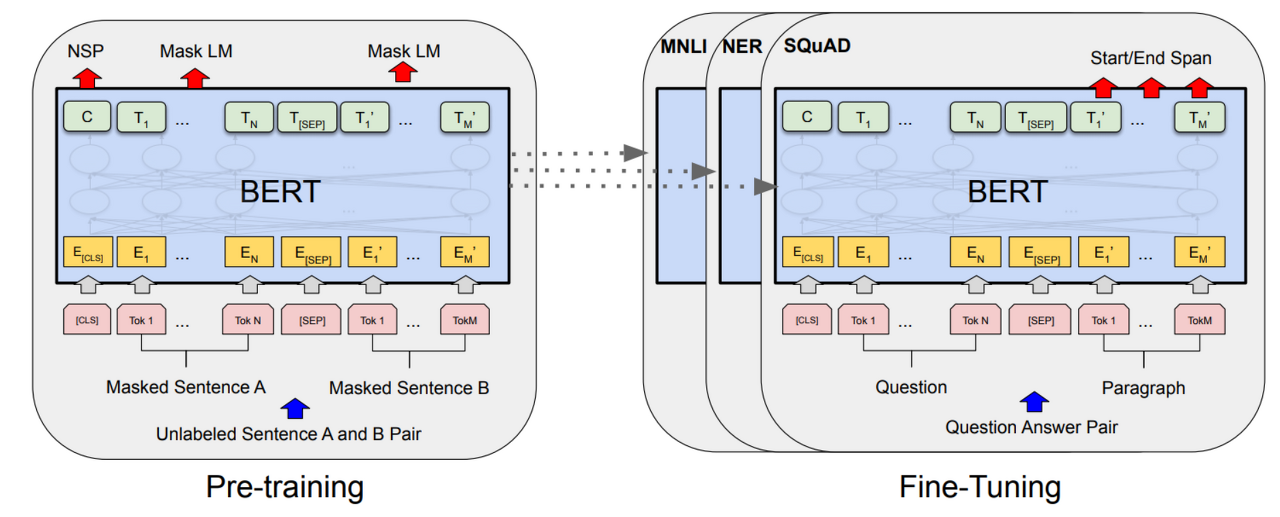
Pre-trainde BERT 모델에 한 개의 output layer를 쌓는 것만으로도 많은 NLP Task에서 SOTA(State Of The Art) 성능을 기록할 수 있다고 한다. (논문 발표 당시)
BERT의 Model Architecture를 살펴보자.
BERT는 Multi-layer bidirectional Transformer encoder이다.
먼저 이후에 언급할 약어에 대해 정리하면 다음과 같다.
- L : number of layers (Transformer block)
- H : hidden size
- A : number of self attention heads
이제 BERT-base 모델과 BERT-large 모델의 모델 아키텍처에 대해 알아보자.
BERT-base 모델 (GPT-1과 성능을 비교하기 위해서 GPT-1과 동등한 크기)
- L = 12, H =768, A = 12
- Total parameters = 1억 1천만개
- OpenAI의 GPT와 같은 모델 사이즈
BERT-large 모델 (BERT의 최대 성능을 보여주기 위해 만들어진 모델)
- L = 24, H = 1024, A =16
- Total parameters = 3억 4천만 개
BERT는 다음과 같은 트랜스포머의 인코더 구조를 사용한다.
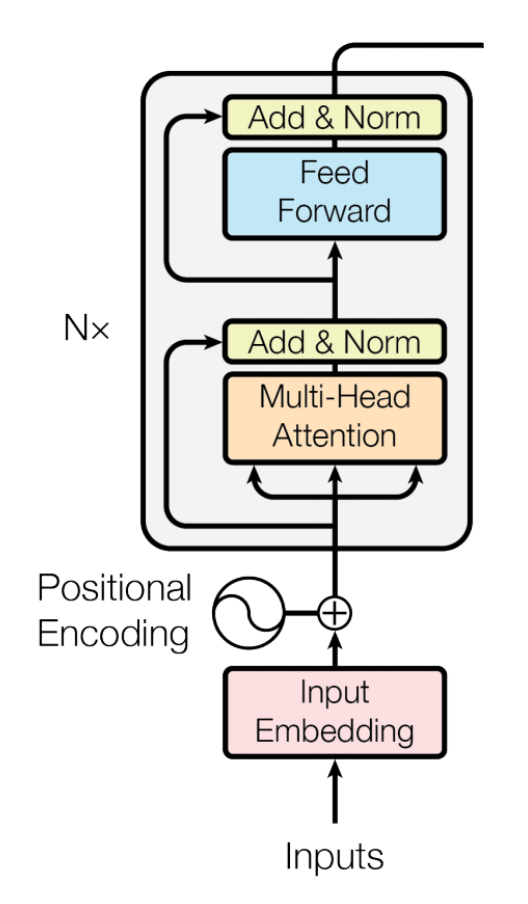
BERT에서 정의하는 sentence는 우리가 흔히 알고 있는 sentence의 정의와 사뭇 다르다.
- 우리가 알고 있는 sentence : S+V+O처럼 하나의 완벽한 의미를 가진 문장
- BERT에서 정의하는 sentence : 연속적인 text의 span
BERT에서 정의하는 sentence는 완벽한 언어학적 문장이 아니어도 된다.
또한 이는 우리가 흔히 아는 문장의 일부분일 수도, 더 긴 것일 수도 있다.
이러한 sentence 하나 또는 두 개가 이루는 것이 하나의 sequence가 된다.
(여기서 sequence와 sentence의 차이를 명확히 알고 넘어가야 추후 모델을 이해함에 있어 혼란이 없을 것이다.)
이제 BERT가 가지고 있는 실제 Input과 output 구조를 살펴보자.
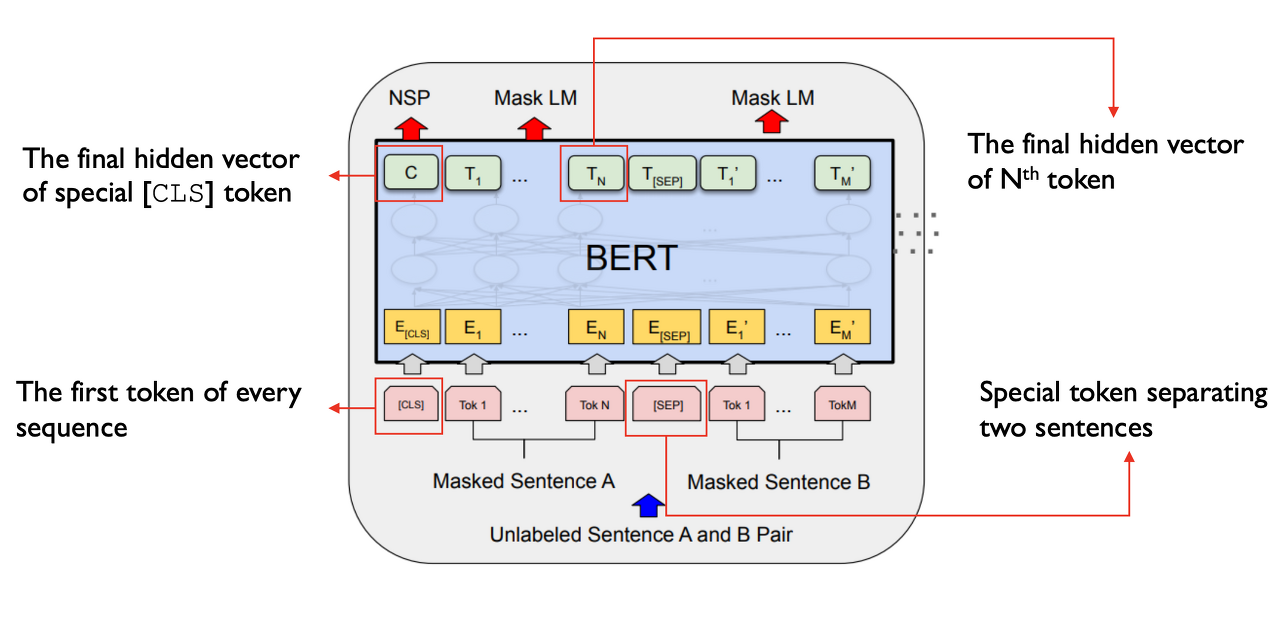
[CLS] 토큰은 모든 sequence의 시작을 의미한다.
[SEP] 토큰은 2개의 sentence를 구분해 주는 토큰이다.
NSP는 앞서 말한 Next Sentence prediction으로 두 개의 sentence가 실제 corpus에서 바로 다음 sentence인지 아닌지를 판별하는 binary classification을 말한다.
Mask LM은 masking 된 토큰을 예측하는 Masked language model이다.
여기서 NSP와 Mask LM을 동시에 학습시키는 게 BERT의 목적이다.
(감성 분류, sentence similarity와 같은 단순한 binary classification을 할 때는 [CLS] 토큰만 가지고 한다.)
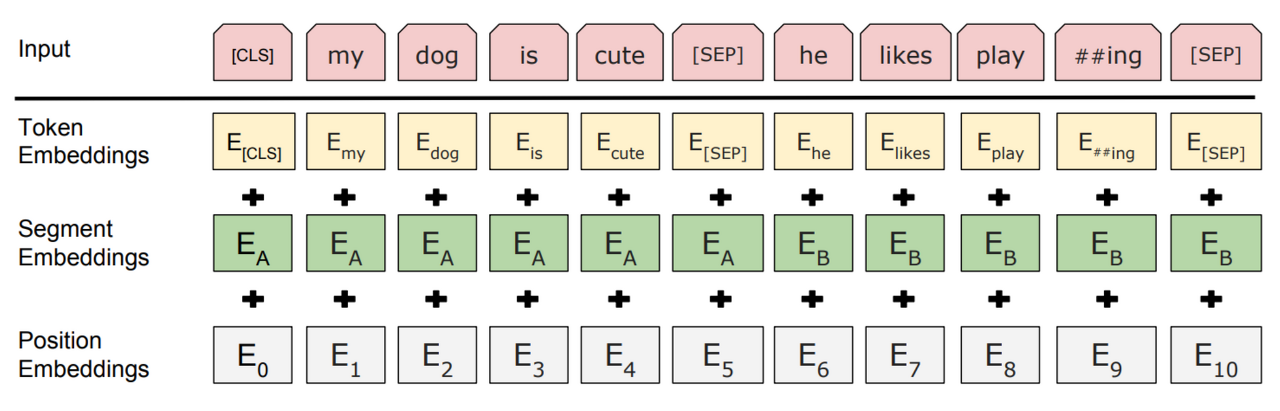
BERT의 Input/Output Representation은 세 Embedding 벡터의 합으로 표현된다.
- Token embedding : 3만 개의 토큰 사전으로 이루어진 WordPiece embedding을 사용
- Segment embedding : 두 개의 sequence가 들어갔을 때 몇 번째 sequence인지 알려줌
- Position embedding : 토큰의 상대적 위치를 알려줌
여기서 세 임베딩은 모두 동일한 차원을 가지기 때문에 단순 합이 가능하다.
- Token embedding에서 사용한 WordPiece 토크나이저
서브워드 토크나이저는 기본적으로 자주 등장하는 단어는 그대로 단어 집합에 추가하지만, 자주 등장하지 않는 단어의 경우에는 더 작은 단위인 서브워드로 분리되어 서브워드들이 단어 집합에 추가된다는 아이디어를 갖고 있다.
- Segment embedding
“I like cats” 와 “l like dogs” 라는 두개의 input이 들어오면 이를 concat 한 후 토큰화를 한다.
이후 [CLS], I, like, cats, [SEP], I, like, dogs 총 8개의 토큰으로 구성된다.
여기서 [CLS] 부터 [SEP] 토큰 까지를 0 으로, I 부터 dogs까지를 1로 표현한다.
이러한 상황에서 Segment Embedding의 파라미터는 1536(768*2)개가 된다.
BERT-base 모델에서 768차원짜리 input 두 개를 학습하는 것이기 때문이다.
여기서 Segment Embedding 자체로 학습이 된다.

BERT의 Task 중 첫 번째로 MLM에 대해서 알아보자.
MLM은 전체 sequence의 15%를 random 하게 [MASK] 토큰으로 바꾼다.
이후 이 마스킹된 토큰을 예측하면서 실제 토큰과 같아지도록 학습을 진행한다.
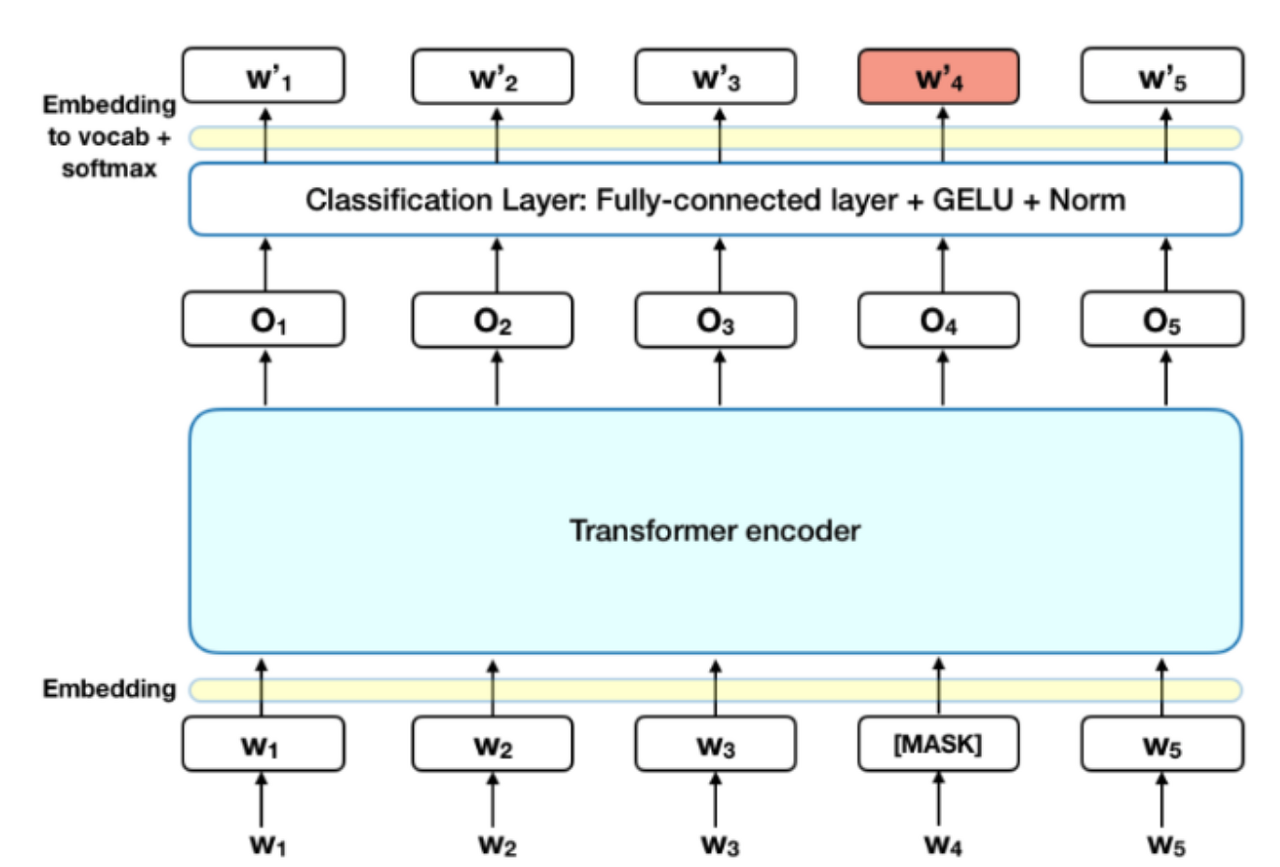
예컨대, w’ 4가 w4가 되게끔 학습을 진행하는 것이다.
BERT Original 논문에서 언급하는 MLM의 문제점이 있다.
MLM은 pre-train을 할 때만 사용된다는 것이다. 이는 pre-train과 fine-tuning 사이에서 [MASK] 토큰에 대해 mismatch가 되는 문제점이 발생한다.
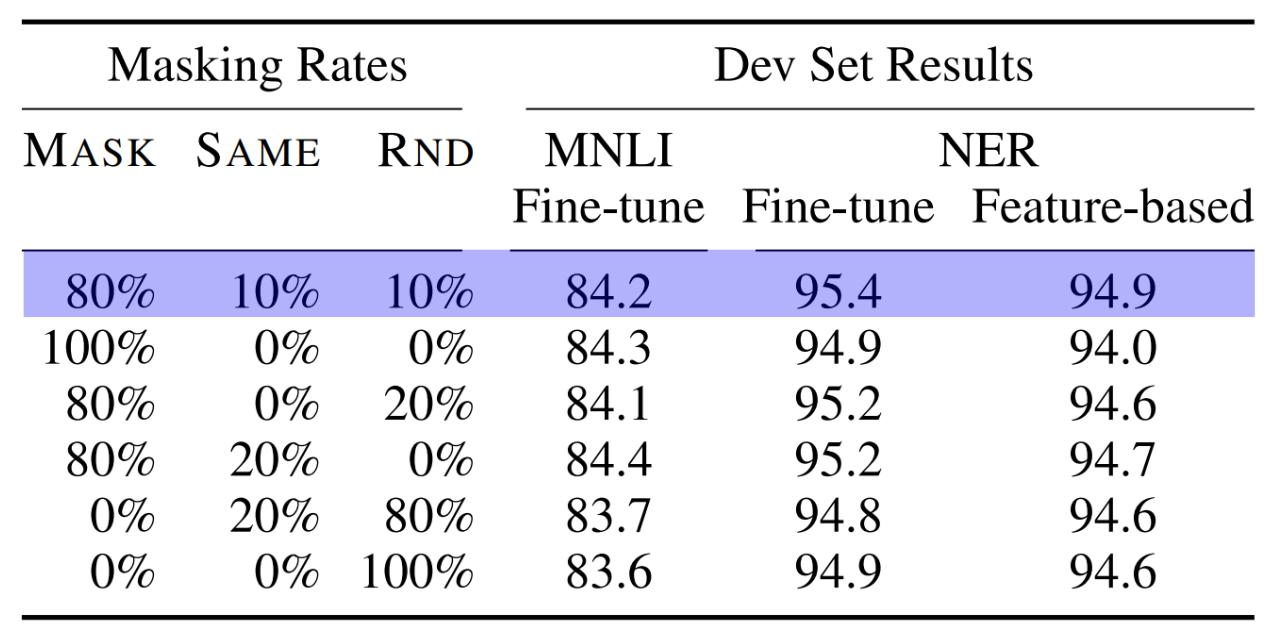
그래서 이에 대한 solution으로 10 번중 8번은 원래대로 마스킹을 하고, 10번 중 1번은 생뚱맞은 랜덤 토큰으로 대체하고, 10번중 1번은 마스킹을 수행하지 않고 원래 토큰으로 둔다.

논문에서는 이 방식을 통해서 8:1:1 비율로 진행을 했을 때 높은 성능을 이뤘다고 하는데, 이는 경험적 실험에 의한 결론이고 논리적으로 검증된 사실은 아니기에 무조건 이 방법이 옳다 라고는 할 수 없을 것 같다.
BERT의 Task 중 두 번째로 NSP에 대해서 알아보자.
ELMo나 GPT는 하나의 sentence씩 입력을 받는 반면, BERT는 두 개의 sentence를 입력받을 수 있다.
NSP는 다음과 같이 동작한다.

하나의 문서 내에 여러 문장이 있다. S1, S2 , …
여기서 Sn과 Sn+1을 연속된 문장이라고 하면 NSP는 두 개의 문장 사이의 관계를 통해 연속적인 문장이면 1, 아니면 0으로 판별한다.
원 논문에서는 QA(질의응답)나 NLI(자연어 추론)과 같은 Task에서 두 문장 간의 관계가 중요하므로 두 문장을 같이 입력받아야 한다고 한다.
또한 저자들의 주장에 의하면 이 NSP방식이 단순함에도 불구하고 QA나 NLI와 같은 Task에서 유의미한 성능 향상을 이뤄냈다고 한다.
NSP의 예시를 또 하나 보면

위와 같은 대화가 있다고 했을 때,
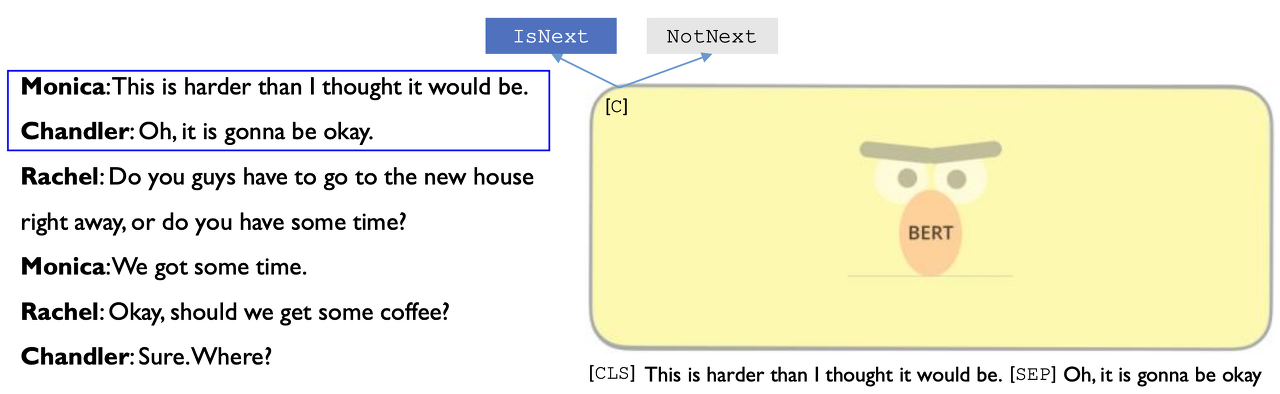
이처럼 연속된 문장은 IsNext로 판별하고
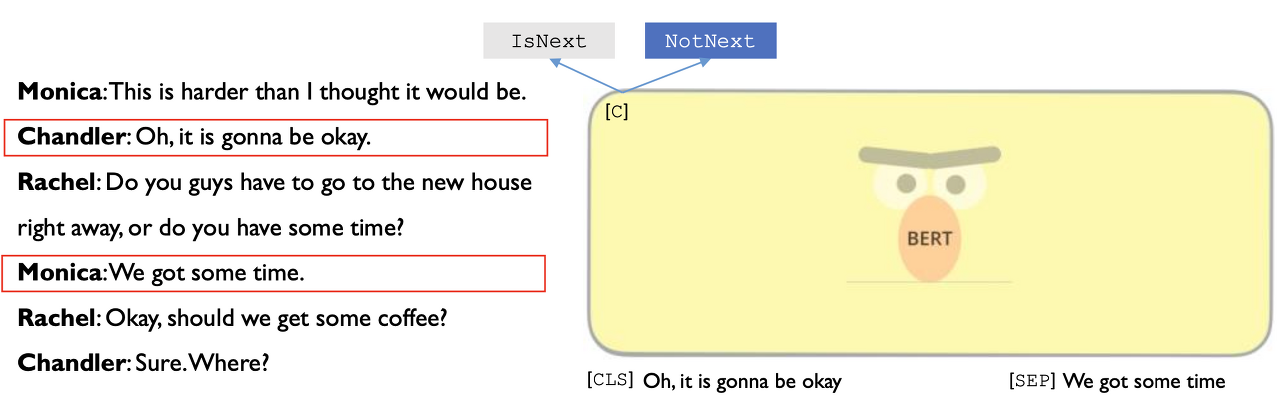
이처럼 연속되지 않은 문장은 NotNext으로 판별한다.
이제 ELMo와 GPT, BERT의 모델 아키텍처들을 비교해 보자.
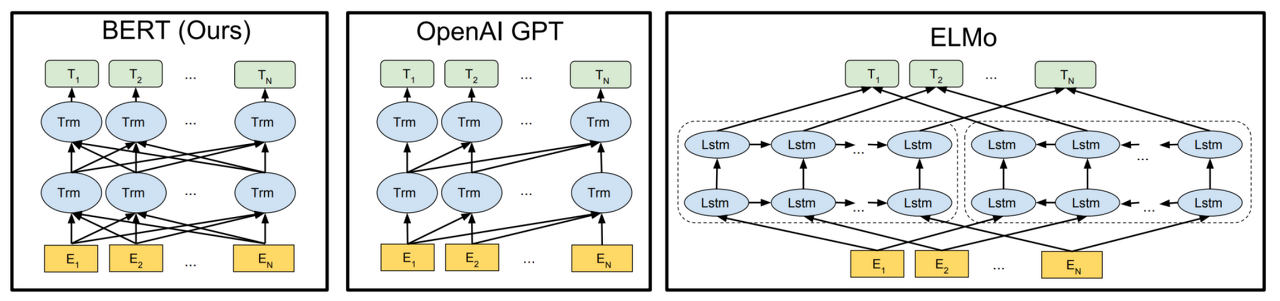
- BERT : Encoder를 가지고 양쪽 방향 동시에 학습. 일정 비율 random 하게 masking
- GPT : Decoder를 가지고 한쪽 방향으로만 학습
- ELMo : forward LSTM과 backward LSTM을 여러 단계 학습. hidden state를 전부 linear combination 해서 최종적인 토큰 생성
BERT를 Pre-training 할 때 사용된 Dataset은 다음과 같다.
- BookCorpus Dataset : 8억 개의 단어
- English Wikipedia : 위키피디아에서 추출한 25억 개의 단어
BERT를 Pre-training 할 때 사용된 Hyper-parameter setting은 다음과 같다.

여기서 Maximum token length는 한 sequence(두 문장 합쳐서)를 의미한다.
또한 밑에서 두 번째 줄에 학습이 너무 오래 걸려서 90%는 sequence length를 128로 제한했다는 걸 고백(?)한다.
BERT를 fine-tuning 하여 할 수 있는 Task들과 그 아키텍처는 다음과 같다.
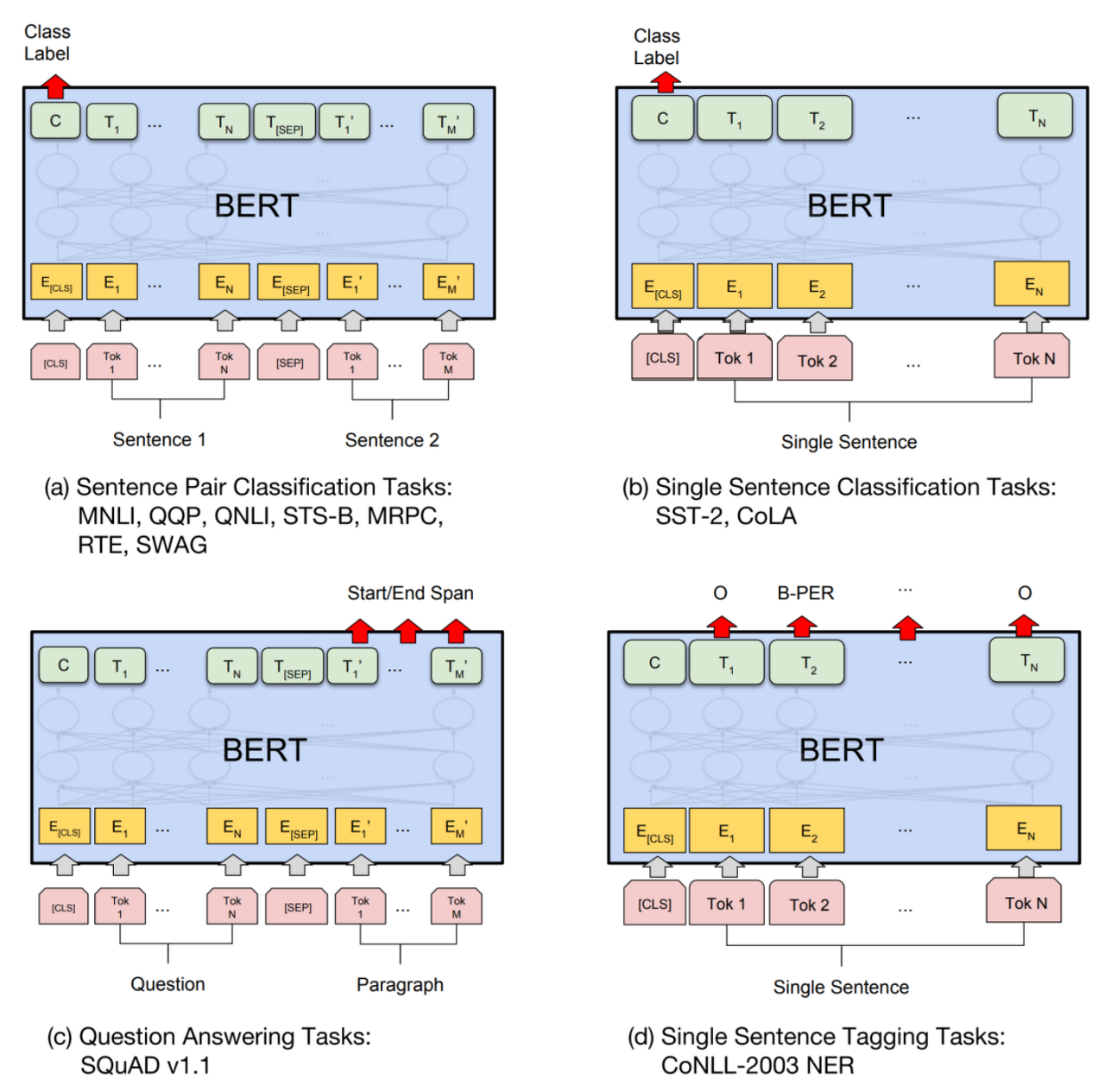
(a)와 (c)는 입력으로 두 개의 sentence를 받는다.
(a)는 단순 범주를 예측하는 Task이고
(c)는 새로운 문장을 생성하는 Task이다.
(b)와 (d)는 입력으로 한 개의 sentence를 받는다.
(b)는 단순 분류 Task이고
(d)는 문장 태킹 Task이다.
여기서 알 수 있는 점은 BERT의 fine-tuning은 pre-trained model 윗 단에 하나의 layer를 쌓는 것만으로도 충분히 구현 가능하다는 것이다.
<Reference>
https://youtube.com/watch?v=IwtexRHoWG0&feature=shares